
This post originally appeared on the Finn AI blog and was authored by Dr. Kenneth Conroy, VP of Data Science at Finn AI. Finn AI is now a part of Glia.
With the advent of deep learning, much of the focus of research has been on developing a model-centric approach to conversational AI. In simple terms, this approach means to gather as much data as possible, label it as best you can, and let the model iron out the inconsistencies. The theory was that the model, given enough data, can handle the integrity issues itself. This approach works very well to get an “okay” version of many problems in place, but only in situations where there are a small number of variables, or where being overly broad and/or frequently wrong is worth the efficiency gains you get from being correct most of the time.
The biggest problem with model centric approaches, however, is that you will hit a wall of accuracy where you can not get any better. Correcting labels or annotating may increase the accuracy on things you’ve already seen before, but this creates inconsistencies elsewhere, so the overall performance does not improve meaningfully. When this happens, your only recourse is to start relabelling things you’ve already labelled. Having “big data” as the baseline means revisiting everything you’ve seen before with more granularity, or with a new labelling strategy. This may not be feasible depending on how much data you’ve already labelled, and is a central reason why lean principles are not that effective for many machine learning/AI tasks.
A second problem is that when it becomes necessary to change your labelling strategy, to make the additional improvements in accuracy or be more precise in your predictions, model-centric usually means your labelling and analysis infrastructure is naively construed in the first place. When you can only imagine a handful of labels to start with, it was never necessary to understand the subtle differences between labels or how the model interpreted those granularities, so you end up not having a means of understanding those differences until it’s too late. You might also have a basic labelling tool, but without feedback loops to prompt annotators, clear documentation, guidance that can scale beyond just yourself as annotators, and robust quality control measures such as gold set examples.
These issues have become more apparent in many fields as we have matured, and much is being written about the importance of having a more data-centric outlook to solving problems. So what is the difference? – Mainly, your attitude towards data. Andrew Ng has a good talk about it here, and further discussion here.
| Model-Centric | Data-Centric |
|
|
When you want a complete solution that can scale with your needs and your customer’s requirements after the POC phase while maintaining high accuracy, we found it very important to take a data-centric approach. With a data-centric approach, instead of relying on the model to find inconsistencies in your data via trial and error, you design a system based on the characteristics of data, then use that to train your models. With a data-centric approach, you can still make use of state-of-the-art models with an optimized architecture, but the quality of the data is more important than the quantity.
Let’s consider an example to show the problems with rushing out with a naive model and relying on a model-centric approach. In our domain of conversational AI in the retail banking space, there’s a need to answer questions relating to technical issues. Many approaches/models available are set up in a way that answers all the questions about technical issues – either by providing a response anticipating what the issue is, or by handing the user to an agent to resolve the problem. What if, however, you want to contain the conversation by being precise enough to consider the type of technical issue the user is having? That might involve relabelling hundreds of thousands of data points that were previously marked as a generic “technical issue”. This also impacts accuracy: a bot with 90% accuracy that answers 1 question is not as good as a bot with 88% accuracy with 50 more granular user goals in place of that initial 1.
User Goal:
- The user has a technical issue.
OR
User Goals:
- The user cannot login to their online banking
- The user has forgotten their password
- The user has said there’s a problem with the banks website
- The user has reported an issue with the banks app
- User is having trouble with an application for a product and would like help resolving that.
- The user is locked out of their account and would like to fix it.
- The user’s account or card is blocked and they would like to fix it.
- … (and 40 more, previously covered “technical issue” user goals)
In one sense, you do need a lot of data to know what the larger set of requirements are, but this can be achieved by focusing on how to adapt to your data needs in real time. Tooling and analytics can help us achieve this, which includes using topic modelling to identify previously unsupported topics or using skilled annotators to comb through the subtle differences between user asks. IQ Visualize is a tooling set we’ve built to understand how the model itself is learning from the underlying data.
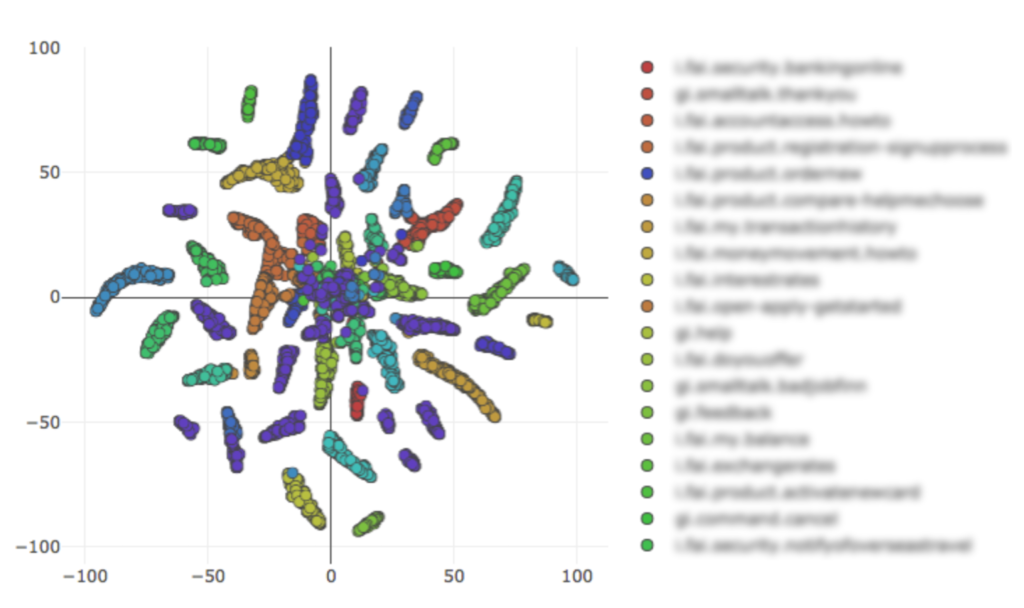
Seeing how this data is being interpreted is helpful: you know where label boundaries are clashing, or where we may combine multiple concepts, but making it interactive adds to its usefulness. The next graphic shows how we can visualize, relabel, and then retrain these utterances at this level of abstraction. These kinds of tools are neglected or wouldn’t exist at all if you take a model-centric approach.
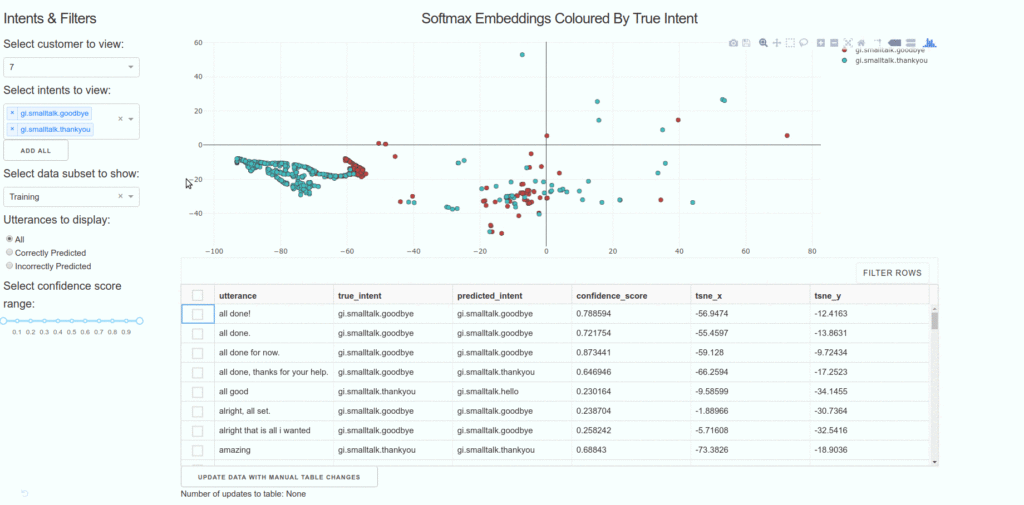
Each time we train a model, we also need to see how any additions, modifications, or further granularity added impacts that version of the model. A robust versioning system is also required to track changes for analytics, and in our case to roll out to all of our customers.

To support your relabelling strategies, allowing inter-annotator agreement and putting the model in the loop will lead to higher quality annotations and knowledge of the capabilities of the wider model. IQ Design has a model-in-the-loop approach to suggesting possible labels for the customer.
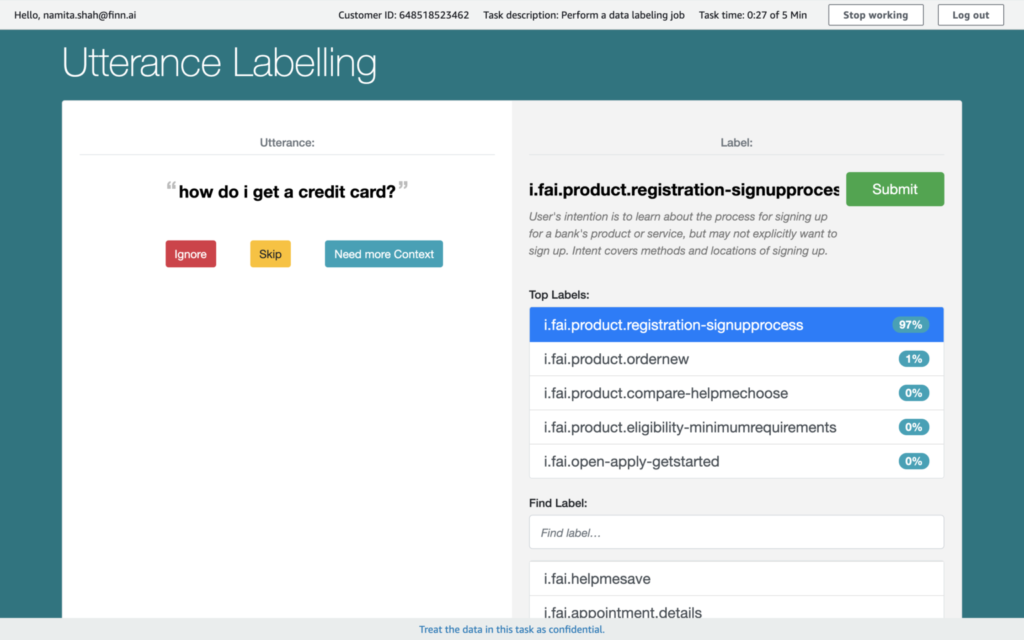
Being data-centric from the beginning of our development into the conversational AI and chatbot space has meant we have an embarrassment of riches when it comes to our understanding and interpretation of language for retail banking. Hundreds of thousands of utterances, used to train over 800 unique user goals for customers, capturing 88.3% of all our users’ needs within the bot makes us a market leader of chatbots for banks and credit unions. Doing it at this granularity is key: we are not deflecting broad topics to call centers or other websites/mobile apps, we can answer these user goals within the conversational interface. Many banks and credit unions are now joining us to serve their members and customers with the intuitive self-service option of conversational AI.


